Importing a large number of Items into Wikibase can be a challenge. This post provides a high-level overview of different importing approaches and their performance.
If you have 10 million Items that need to be imported into your fresh and shiny Wikibase wiki, you better hope it goes faster than 5 Items per second. At that rate, the import would run for just over 23 days! Yet many institutions have more than 10 million Items to import, and several of the tools out there provide import speeds in the order of 5 Items per second.
At The Wikibase Consultancy we have helped some of our Wikibase clients with the import of large amounts of data. One of those clients started by using QuickStatements, achieving an import speed of 3 to 4 Items per second. They almost doubled the speed by using a script on top of WikidataIntegrator, a python library for making API requests to Wikibase. We then came in, assessed the situation and created a PHP script, allowing imports for up to almost 100 Items per second. There are ways to go even faster, though as we will see, faster approaches come with their own tradeoffs.
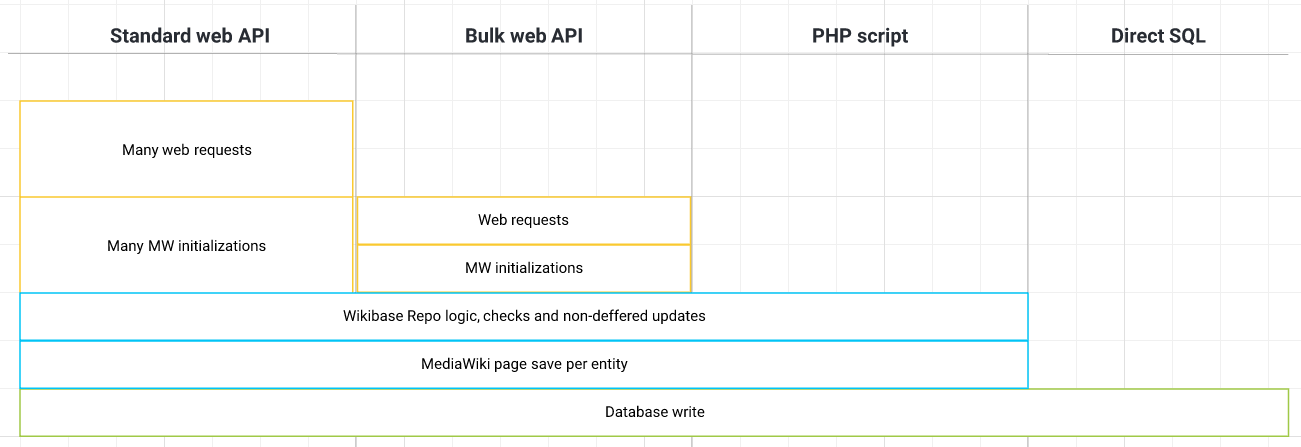
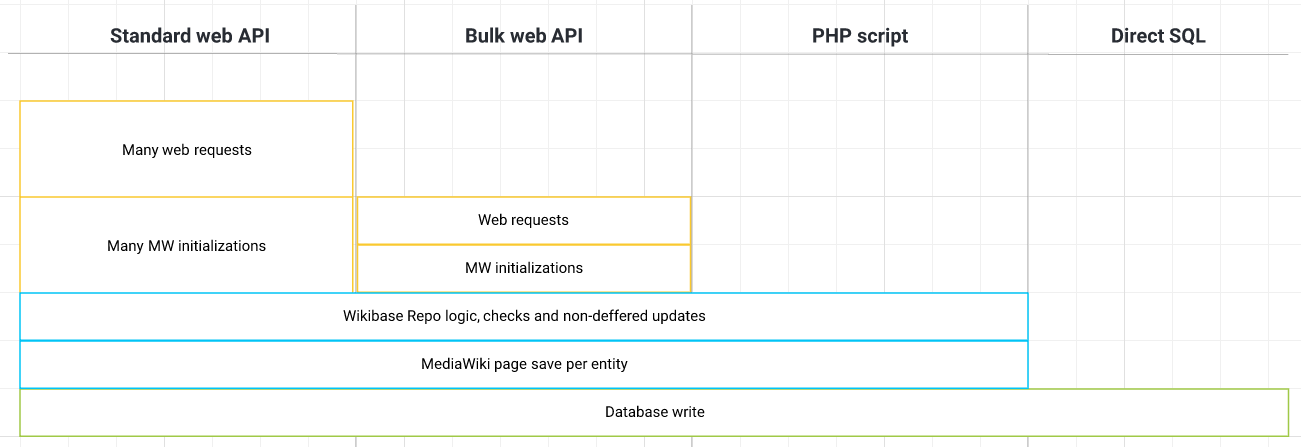
In this post, we will look at 4 broad categories. From slowest to fastest: using the standard web API, using a bulk web API, using a PHP script, and directly running SQL against the database.
Standard web API
By far the most common approach is to use the standard web API of Wikibase. This is also the slowest approach.
Despite being the slowest, it does come with a number of appealing advantages:
- This API already exists.
- The API is stable, well documented, and widely used.
- You can use whatever programming language you like to talk to the API.
- You do not need to understand much about the underlying software implementation.
Many popular tools such as QuickStatements, pywikibot and WikidataIntegrator fall into this category. Even if you are not using the API directly, these tools are. This places an upper bound on the performance you can achieve.
The reason this approach is so slow is that for each Item or Entity that you import, a new web request is created. In cases of some tools, you might even be doing multiple web requests per Entity, for instance one per Statement. MediaWiki then handles each web request by initializing itself and Wikibase. After that a whole bunch of Wikibase and MediaWiki logic happens, followed by writes to the database. For a detailed breakdown, see What happens in Wikibase when you make a new Item?, an excellent post by Addshore.
Bulk web API
We can avoid many HTTPS requests, and corresponding initializations of the MediaWiki stack, by using a bulk web API. This API allows the creation of multiple Entities in one request.
No one is using this approach yet, since there is no such bulk API yet. Implementation of such an API requires building on top of various Wikibase services, and having an understanding of Wikibase internals. Even so, it is an interesting option, and it would be a nice improvement for various users.
How much speed up can we expect? Because the bulk API itself would still need to create Entities one by one via Wikibase PHP services, only some performance is gained. Perhaps a factor of 5, or even 10. Possibly more when using fancy parallelization, though I am not sure that would work within MediaWiki.
Further enhancements are possible to the Wikibase PHP services, raising the upper bound of what is ultimately possible with a bulk web API. Such enhancements would also benefit the regular API and the PHP script approach described in the next section. Enhancing the performance of the Wikibase PHP services is not a simple task. It requires a deep dive, understanding of the environment and following of Wikimedia development processes. A good starting point is Addshores recent Profiling a Wikibase item creation blog post.
PHP Script
While the bulk web API approach reduces the number of web requests and initializations of MediaWiki, the PHP script approach eliminates those entirely.
We have used this approach with our clients. Including the German National Library, where our script can import their ~10 million item GND dataset in about a day.
A script is created that takes the data of the client in the clients format, and then creates Wikibase Entities based on this data. The script talks directly to Wikibase and MediaWiki PHP services.
While this approach is significantly faster than using the standard web API, and faster than the theoretical bulk web API, it does come with a number of downsides:
- Requires developer familiarity with the environment and the Wikibase and MediaWiki codebases
- Can not be used or built upon by external tools
- Is exposed to less stable internal Wikibase APIs, possibly causing reduced compatibility between multiple Wikibase versions
Direct SQL
By directly executing SQL against the database, we can gain significantly higher performance than even with the PHP Script.
There is RaiseWikibase, which can import up to a million Entities per hour. There is also a Java tool or library that takes a similar approach. Leave a comment if you remember its name.
While the direct SQL approach is by far the fastest, it comes with additional downsides:
- Skips MediaWiki and Wikibase logic
- Constraints are not applied
- Secondary persistence is not initialized or updated
- RecentChanges
- Wikibase terms
- Search index
- Statistics
- …
- Normalization and other logic are not applied
- Requires developer familiarity with the internal persistence structure of Wikibase
- Can not be used or built upon by external tools
- Binds to internal implementation details, possibly causing reduced compatibility between multiple Wikibase versions
Skipping MediaWiki and Wikibase logic creates quite a few complications. Direct SQL import might still be the tradeoff for those with significantly more than 10 million items.
What To Work On
When starting with a bulk import project, it is good to have a high-level understanding of the various approaches to importing into Wikibase. Including their complication and the degree to which they can be optimized.
My hope is that this blog post gives people pause before writing yet another Python script on top of the standard web API. At least when it comes to bulk import.
There are various things that could be done to improve the import options in the Wikibase ecosystem, including
- Improvements to Direct SQL Import tools, especially around inclusion of “secondary data/indexes”
- Improvements to how quickly Wikibase Repo saves entities. Possibly including new ways to turn off some of the expensive checks during bulk imports.
- Creation of a general purpose bulk import PHP script
- Creation of a general purpose bulk import web API
Additionally, it is possible, and typically much easier, to create a solution tailored to your own needs, rather than something general-purpose. Which of those approaches makes sense to invest effort into really depends on your project, use cases, and priorities.
Making Something Happen
Bulk import performance was a big topic during last weeks Wikibase Stakeholder Group meeting. This post was written in big part to add additional context and structure to that conversation. If you are investing effort into creating tooling around Wikibase, or are (planning to become) a significant user of the software, I recommend looking into the Stakeholder Group and possibly joining the conversation there.
At The Wikibase Consultancy we have worked on Wikibase import before, and could potentially help you with your own Wikibase project. Do you wish to commission the creation of a fast import script or a general-purpose bulk web API for Wikibase? Get in touch with us. Our Wikibase development expertise is unmatched, and we provide various other Wikibase services.

I guess: https://github.com/jze/wikibase-insert (java tool)